In AI / Machine Learning Projekten entstehen häufig große Mengen an experimentellen Ergebnissen, in denen sich Data Science Teams leicht verirren. Systematische Kontrolle und Strukturierung der Experimente hilft dabei, produktiver und zielführender zu arbeiten.
Was ist eigentlich ein Data Science Experiment?
Unter einem Data Science Experiment versteht man den Prozess, in dem man ein Machine Learning Modell mit einem bestimmten Design und festgelegten Parametern auf einem Teil der Daten trainiert und auf einem anderen Teil validiert. Die Leistung des Models auf den Validierungsdaten ist das Ergebnis des Experiments und wird durch Metriken wie zum Beispiel Accuracy (Genauigkeit der Klassifizierung) gemessen.
Wo entstehen in einem Data Science Projekt Experimente?
Bei der Beantwortung dieser Frage hilft die Orientierung an dem (- bei AIM in dieser Form definierten -) Arbeitsablauf in einem Data Science Projekt:
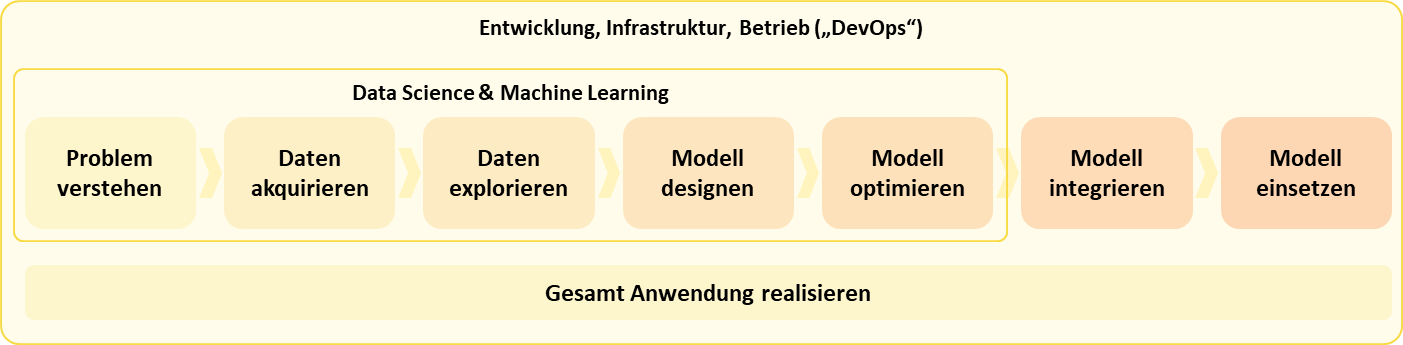
Zunächst muss das Data Science Team sowohl die Problemstellung als auch die Datenstruktur und -qualität genau analysieren. Sorgfältiges Arbeiten kann einem hier eine Menge späterer Probleme ersparen.
Wenn man sich mit der Aufgabe und den Daten vertraut gemacht hat, folgt die Phase des Modell Designs. Hierbei wird eine Auswahl an geeigneten Vorverarbeitungs-Methoden, Modellen und Hyperparameter getroffen, die realisiert, getestet und verglichen werden müssen. Den vielversprechendste Ansatz schickt man dann in die Phase der Optimierung hinsichtlich Laufzeiten, Ressourcenbedarf und Stabilität, bevor man das fertige Modell in ein größeres System integriert.
In einem einzigen solchen Durchlauf wird aber häufig noch kein hinreichendes Ergebnis erzielt…:
Warum entstehen so viele Experimente?
Selbst wenn der Prozess so geradlinig wie beschrieben abläuft, können in der Phase des Modell Designs und der Model Optimierung schon massenweise Experimente anfallen, da es häufig etliche verschiedene Optionen mit jeweils unzähligen Konfigurationsmöglichkeiten gibt. Eine einzelne Hyperparameter-Optimierung kann dabei schon gerne mal einige hundert Experimente umfassen.
In der Praxis werden diese Schritte sogar oft mehrmals iteriert, sei es weil neuere Forschungsergebnisse berücksichtigt werden sollen oder bei der Modellierung, der Datenanalyse oder der Datenakquisition neue Erkenntnisse gewonnen wurden. Ebenso kann es sein, dass sich aus dem Feedback des Kunden und der Anwender neue Anforderungen ergeben.
Wofür braucht man Experiment-Kontrolle?
Hieraus wird klar, was passiert, wenn kein vernünftiges System für die Kontrolle der Experimente existiert. Selbst wenn ein Data Scientist alleine arbeitet, wird es schwer, unzählige Ergebnisse zu vergleichen, zu reproduzieren und darauf basierend zielgerichtete Entscheidungen zu treffen, wenn er seine Experimente nicht systematisch organisiert.
Wenn darüber hinaus die Ergebnisse verschiedener Team Mitglieder oder verschiedener Lösungsansätze abgestimmt und vom Product Owner verstanden werden sollen, wird ohne eine solche Ordnung das Durcheinander perfekt. Die individuelle Wiedergabe in Notebooks (z.B. Jupyer oder Zeppelin) und lokale Speicherung führen in der Praxis erfahrungsgemäß eher zu unproduktivem Chaos.
In unseren Teams produzieren wir jede Woche für verschiedenste Aufgabenstellungen und Modelle viele Messergebnisse. Daraus haben sich folgende Anforderungen unser System zur Experiment-Kontrolle ergeben:
Einheitliche Strukturierung:
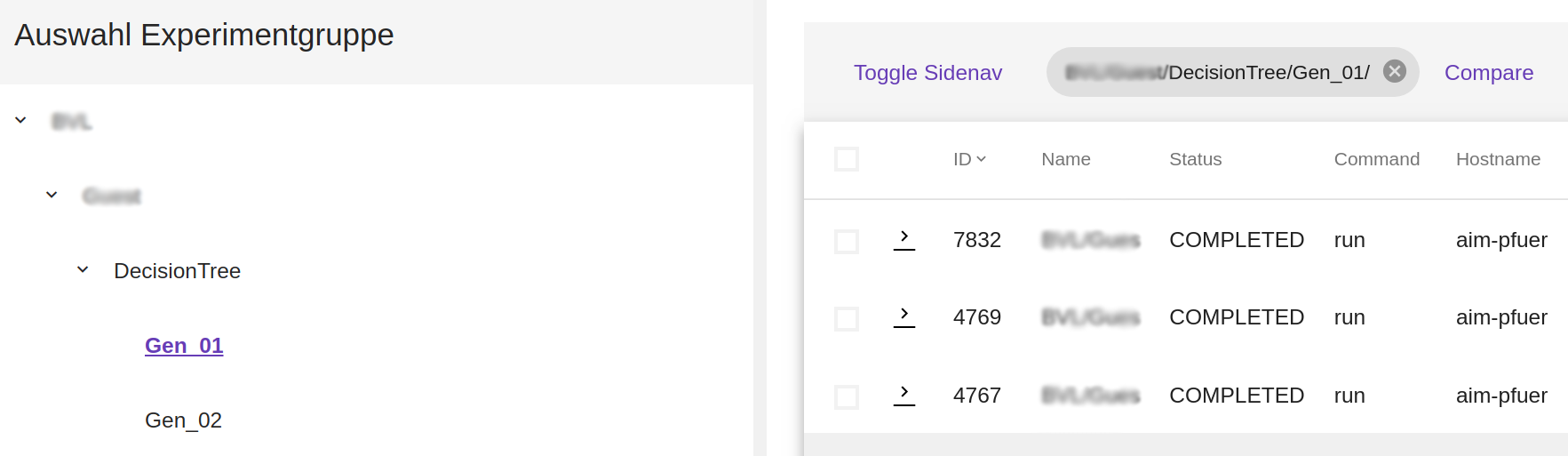
Ein Experiment muss leicht wiederauffindbar sein und es muss erkennbar sein, welcher Phase der Modellierung dieses entsprungen ist. Hierfür eignet sich nach unserer Erfahrung folgende Aufteilung:
Projekt > Aufgabenstellung > Modell > Generation.
Reproduzierbarkeit:
Um eine vernünftige Diskussionsgrundlage zu erhalten, muss man Experimente so abspeichern, dass ihre Ergebnisse für jeden reproduzierbar sind. Dafür braucht man den ausgeführten Code, Informationen zur Konfiguration, zu den Abhängigkeiten und dazu, welche Version des Datensatzes verwendet wurde.
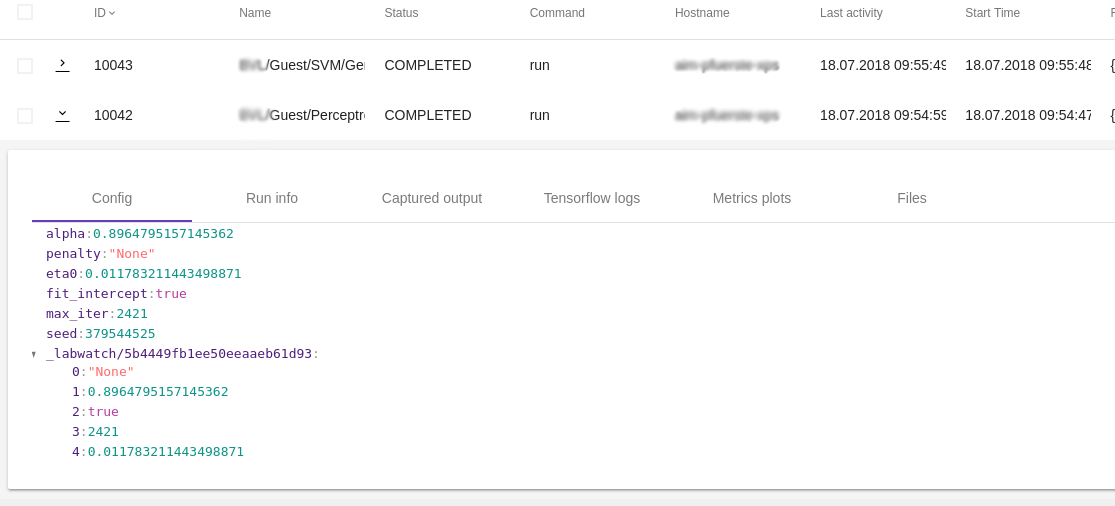
Experiment-Details
Transparente Auswertung und Vergleichbarkeit:
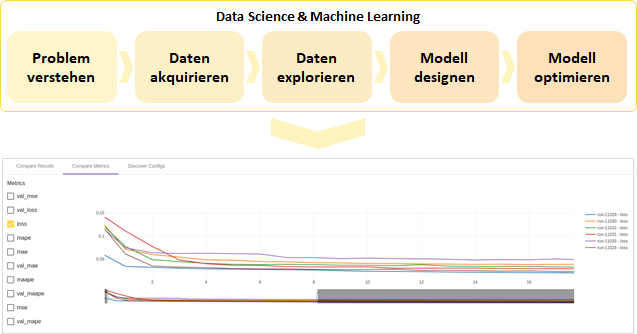
Um effizient Informationen für Entscheidungen extrahieren zu können, muss es Möglichkeiten geben, Ergebnisse zu analysieren. Beispielsweise möchte man bestenfalls mit nur wenigen Klicks herausfinden, welches Modell auf einem Datensatz die beste Leistung erzielt hat, welche Konfiguration einer Modellgeneration das beste Ergebnis in einer bestimmten Metrik geliefert hat oder wie sich bestimmte Metriken entwickelt haben.
Viele Unternehmen versuchen mittlerweile, das Potential von künstlicher Intelligenz für sich zu nutzen und ihre eigenen Data Science Teams aufzubauen. Dafür braucht es meist erst eine gewisse Lernkurve, um Struktur in die Arbeit zu bringen und Abläufe effektiv und effizient zu gestalten. Wir teilen gerne unsere Erfahrungen mit Ihnen und beraten Sie zu Vorgehensweisen und Werkzeugen für Data Science Teams. Kontaktieren Sie uns!
