In den letzten Monaten haben wir neben unseren dedizierten Server Systemen eine vollständige Systemlandschaft auf den Amazon Web Services (AWS) aufgebaut. Der Grund wieso wir uns gerade für AWS entschieden haben ist, dass wir zum einen einen hohen Grad an Automatisierung aufgrund der API erreichen können und zum anderen die Möglichkeiten des Zugriffs auf massive Ressourcen Pools.
Warum IaaS für Machine Learning Anwendungen?
Ein Hauptargument für „Infrastructure as a Service“ sind die speziellen Lastanforderungen von Machine Learning Projekten. Die Last verteilt sich nicht relativ gleich verlaufend auf bestimmte Zeiträume jeden Tages wie es zum Beispiel bei einem Webshop der Fall ist. Vielmehr gibt es unregelmäßige Peaks bei der Exploration neuer oder beim Training komplexer Modelle, zu denen viele Ressourcen benötigt werden – danach fällt der Bedarf relativ stark ab. Ein klassisches Model wäre ausgesprochen ineffizient: entweder aufgrund hoher Kosten für größtenteils ungenutzte Ressourcen oder aufgrund hoher Warte- und Turnaroundzeiten bei Exploration und Training.
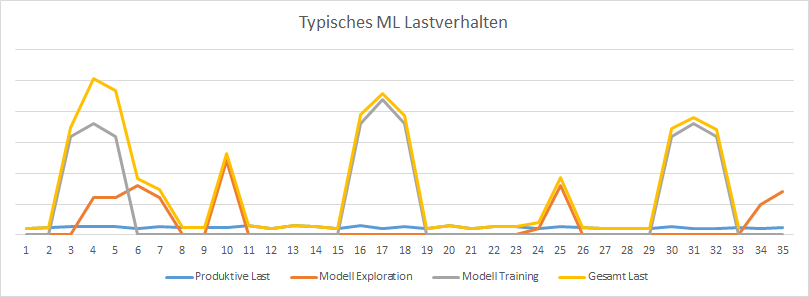
In einem unserer Projekte wäre z.B. eine eigene Maschine mit 2 TB Arbeitsspeicher notwendig gewesen, die dann zwar Vollzeit zur Verfügung stünde – aber zu 90 % im Monat nicht ausgelastet gewesen wäre. In anderen Projekten sind für das effiziente Training von Deep Neural Networks GPUs erforderlich – welche in der Regel nicht zu den üblichen Systemkomponenten gehören und häufig daher auch recht teuer zu beschaffen sind. Und genau an dem Punkt liegen die Vorteile für uns bei AWS auf der Hand:
- Schnelles Deployment der eigenen Infrastruktur über Ansible und der AWS API
- Nahezu keine Limitierung des Scale-Outs (sowohl Vertikal als auch Horizontal)
- Flexible Storage Optionen wie z.B. AWS S3 oder AWS EBS
- Die Sicherheit eines eigenen „Virtuellen Datacenters (VPC)“ innerhalb von AWS
Amazon arbeitet aktuell massiv am Datenschutz Thema und will somit auch deutschen und europäischen Datenschutzbestimmungen gerecht werden. Dazu wird es aber zu einem späteren Zeitpunkt einen Nachfolge Artikel geben.
Konkreter Use-Case
Um unsere verschiedenen Anforderungen abzudecken, haben wir einen ersten Entwurf dazu skizziert, welches den kompletten Workflow darstellt.
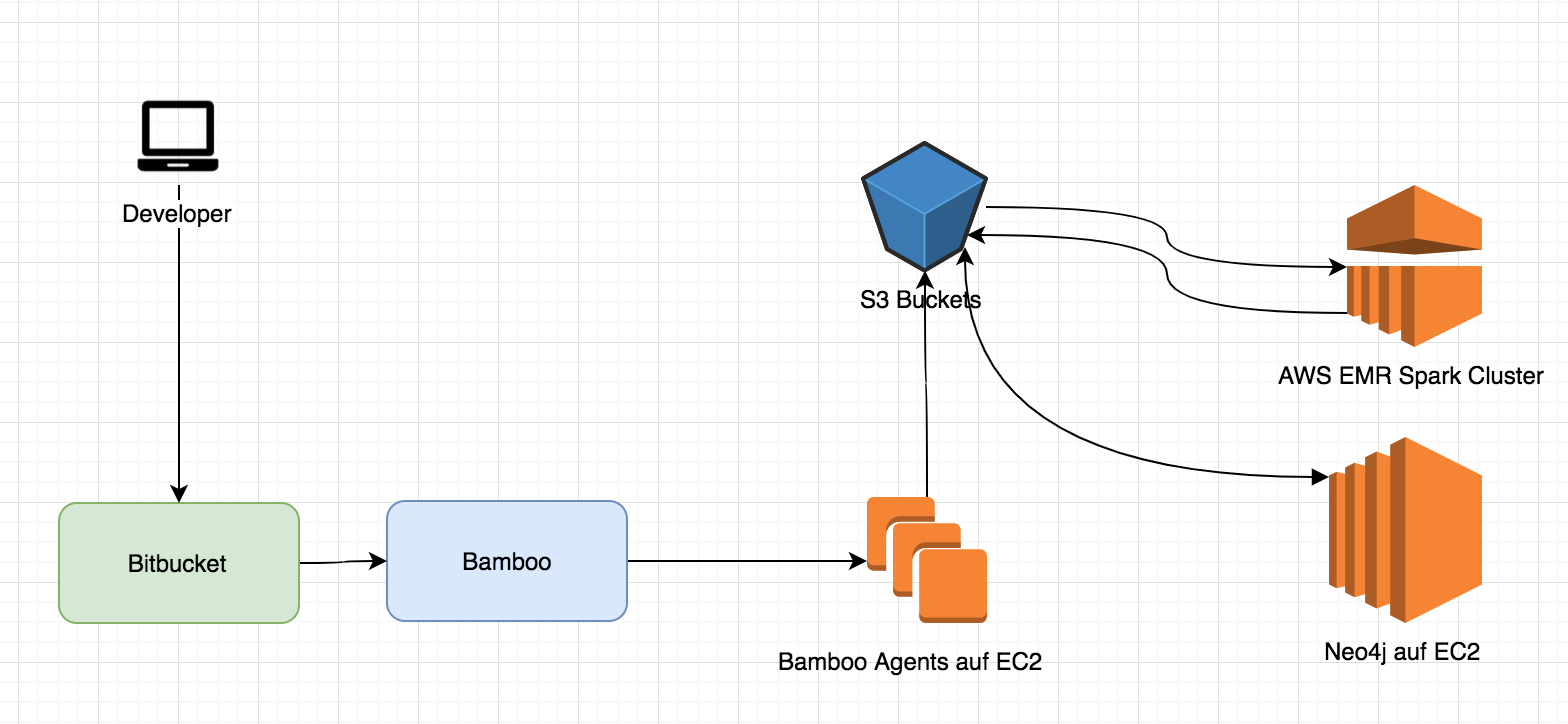
Wir verwenden Atlassian Bitbucket für die Code Repositories, in denen die Entwickler ihre Code Basis einchecken. Das Testing des Codes und der Build Prozess der Artefakte erfolgen dann in Atlassian Bamboo. Dort nutzen wir als Agents die „Elastic Bamboo“-Agents um somit keine zusätzlichen Maschinen für die Agents dauerhaft laufen lassen zu müssen. Diese werden bei Bedarf hochgefahren, die erzeugten Daten werden gegebenenfalls in S3 kopiert und anschließend wieder herunter gefahren.
„Cattle“-Prinzip mit Ansible
Die Maschinen, welche nach Dev / Test und Prod eingeteilt sind, werden ebenfalls maximal dynamisch verwaltet. Die Idee ist, dass jede Maschine ersetzbar ist und somit das Ganze einem temporären Prinzip unterliegt – genannt „Cattle“-Prinzip. Sollte also eine Maschine mal Probleme machen, kann man sie einfach abschießen und neu deployen.
Dieses Prinzip nutzen wir auch häufig für unsere Apache Spark Jobs. Dort gibt es glücklicherweise von AWS EMR bereits einen Dienst, welcher sehr effektiv nutzbar ist. Wir können damit eine wesentlich größere Anzahl an Ressourcen mieten und das nur zu den Zeiten, zu denen wir sie wirklich brauchen.
Alles bei AWS – gibt das nicht einen Vendor Lock In?
Beim Design der Infrastruktur war uns wichtig, dass wir trotz der Konzentration auf AWS unsere Abhängigkeiten gering halten. Zum Provisionieren der virtuellen Maschinen und weitere entsprechende Aufgaben nutzen wir ausschließlich Ansible mit den passenden Modulen. Somit umgehen wir einen strikten Vendor Lock In. Vorläufig erscheint uns aber auf Basis unserer Marktrecherchen AWS in diesem Umfeld als beste Alternative.
Optimierungsbedarf?
Der Trend geht von IaaS (Infrastructure as a Service) hin zu IaaC (Infrastructure as a Code). Somit wird der Automatisierungsgrad soweit voran getrieben, dass es vollkommen irrelevant ist, bei welchem Provider man die Infrastruktur bezieht. Zu berücksichtigen sind dabei natürlich jeweils Security Themen – aber letztendlich kann man seine komplette Umgebung einfach mit einem Tastendruck nach Bedarf hoch und runter fahren.
Interessiert an einem Austausch zu diesem Thema? – Dann nehmen Sie mit uns Kontakt auf!
