
Machine Learning Algorithmen können Muster in sehr komplexen Datenstrukturen und in großen Datenmengen erkennen. Menschen dagegen sind in der Lage, anhand weniger Beispiele unter Nutzung ihres Allgemein- und Kontextwissens zu generalisieren. Aus seinem Erfahrungsschatz kann ein Mensch in Bildern, Texten und Videos Objekte wie z.B. Symbole schnell und leicht erkennen. Das „Human in the Loop“ Konzept verbindet die Stärken von Mensch und Maschine zu einem integrierten, interaktiven System beziehungsweise Kreislauf.
Die Kombi macht’s:
Interaktives Lernen zwischen Mensch und Maschine
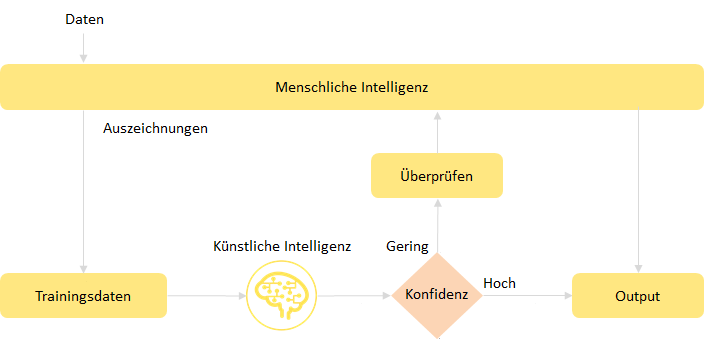
Human in the Loop“ Systeme kombinieren Supervised Learning mit Active Learning und sind ein wichtiger Baustein von KI Anwendungen. Bei Supervised Learning wird ein ML Modell von Menschen mit der „Wahrheit“ bezüglich der Aufgabenstellung ausgezeichneten Daten trainiert, um möglichst genaue Vorhersagen zu liefern.
Dies reicht aber oft nicht unmittelbar aus, um eine hohe Leistung zu erreichen – sei es, weil die Menge an Trainingsdaten zu gering ist, diese nicht informativ genug sind oder die Klassenverteilung unausgeglichen ist.
Hier kann Active Learning zum Einsatz kommen: wo das Modell sich unsicher ist oder Fehler gemacht hat, können Menschen mit ihrem Feedback das System Stück für Stück verbessern. Diese Nutzung der (Un)sicherheit, der Konfidenz, ist vergleichbar mit Auto ML Ansätzen auf Basis Bayesscher Optimierung – nur dass in diesem Falle nicht die Modell Parameter optimiert, sondern gezielt und direkt Trainingsbeispiele erzeugt werden. Falsche, d.h. von der Auszeichnung („Ground Truth“) abweichende Vorhersagen können ebenfalls genutzt werden, geben aber dem Menschen nur Hinweise, wie weitere Auszeichnungen erfolgen sollten.
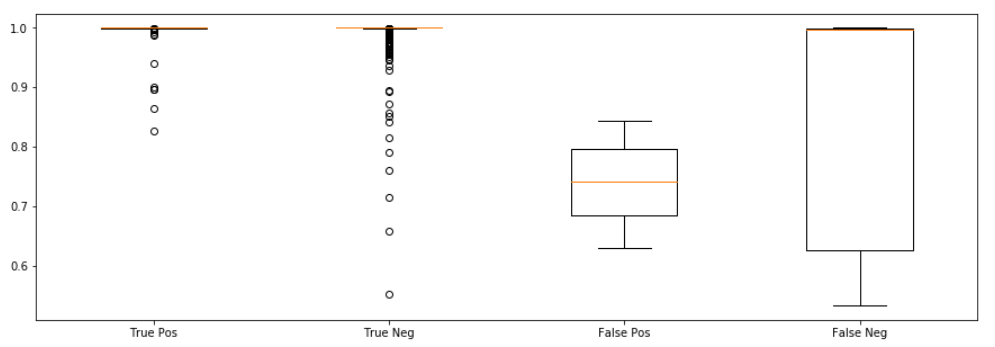
Die obige Abbildung zeigt beispielhaft über sogenannte Boxplots die Verteilung von Konfidenzen für korrekte und falsche Vorhersagen einer binären Klassifizierung (positiv/negativ). In diesem Fall ist deutlich zu sehen, dass falsche Vorhersagen (False Pos/Neg) stärker auf niedrigere Konfidenzen verteilt sind. Natürlich ist dies nicht immer so ideal, aber häufig kann dies gut genutzt werden, um schwierige Datenpunkte zu finden und auszuzeichnen.
Drei Erfolgsbausteine von „Human in the Loop“ Systemen:
- Ein effizientes und schnelles Verfahren für Modell Training und Vorhersage.
- Ein zweckdienliches Verfahren zur Identifizierung informativer Beispiele.
- Ergonomische Werkzeuge für die Auszeichnung von Trainingsdaten.
Werkzeuge für die Auszeichnung
Beispiel: Machine Vision
Die Realisierung entsprechender ergonomischer Werkzeuge ist daher einer unserer Schwerpunkte. Diese Werkzeuge dienen dabei zwei Hauptzwecken:
- Die Auszeichnung von Trainingsdaten für ML-Modelle
- Die Überprüfung von Vorhersagen von ML-Modellen
So wird der Trainer dabei unterstützt, die notwendige Menge an Trainingsdaten in möglichst kurzer Zeit und zielgerichtet auf die Verbesserung der Modellleistung zu erzeugen sowie danach die von den Modellen vorhergesagten Ergebnisse möglichst effektiv weiter zu verwenden. Dabei erfordern verschiedene Aufgaben im Detail passende Ausprägungen der Werkzeuge – am Beispiel von Machine Vision sind z.B. folgende Fälle zu unterscheiden:
- Single/Multi Label: Vergabe eines oder mehrerer, unabhängiger Labels
- Binary/Multi Class: Klassifizierung von nur zwei Klassen (z.B. positiv/negativ) oder vieler Klassen pro Label
- Gegenstand: Bezug auf das gesamte Asset (Bild bzw. Video) oder nur Teilen desselben (Boxen, Segmente bzw. Bilder)
„Label“ bezeichnet dabei den/die Zielwerte der jeweiligen Aufgabenstellungen, die vom Trainer ausgezeichnet werden können und für die das jeweilige Modell seine Vorhersagen macht.
Ablauf des Trainings
Das ML-Modell sagt vorher, ob ein bestimmtes Objekt in einem Bild vorhanden ist. Falls dies der Fall ist, wird eine Bounding Box um das Objekt visualisiert, für die die vorhergesagte Klasse und die Konfidenz, d.h. die diesbezügliche Sicherheit des Modells, zur Verfügung stehen. Der Trainer kann gezielt unsichere Vorhersagen im gesamten Datenbestand selektieren. Unsichere, aber korrekte Vorhersagen kann er bestätigen und inkorrekte Vorhersagen kann er mit der korrekten Auszeichnung „kontern“. So kann der Trainer dem Modell gezielt schwierige Fälle beibringen und mit möglichst wenigen Beispielen einen schnellen Lerneffekt erzielen. Das Werkzeug kann aber auch von Endanwendern genutzt werden, um die Ergebnisse einer Vorhersage überprüfen und weiter zu verarbeiten. Bei einer großen Menge von Ergebnisdaten können sie gezielt diejenigen, die korrekt sind, zur weiteren Nutzung markieren.
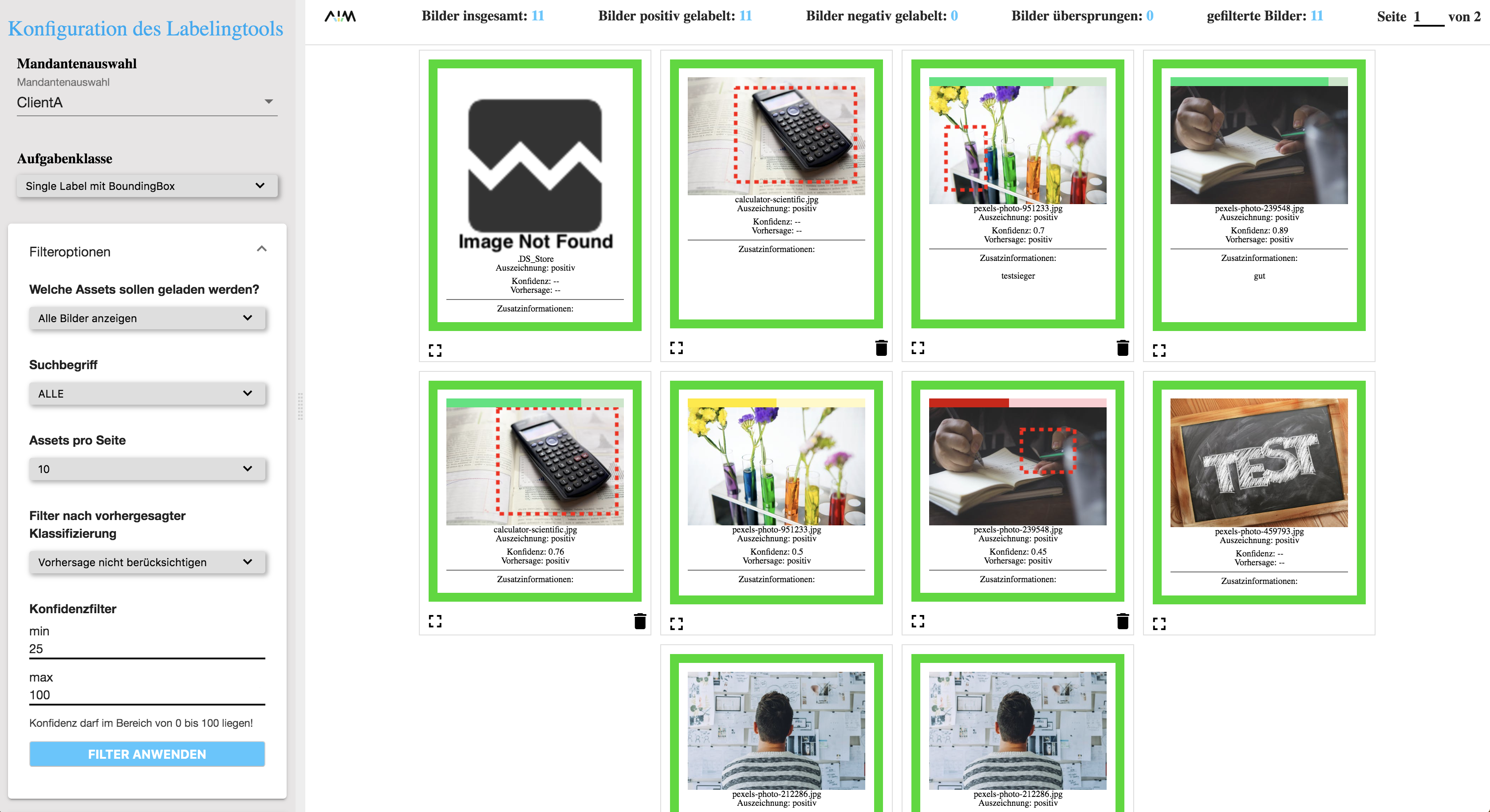
Aus unserer Erfahrung hilft dieses System bzw. dieses Werkzeug enorm, um maschinelle Systeme effizient zu trainieren. Und diese wiederum unterstützen so die Anwender auf die bestmögliche Art und Weise.
Beispiel: Intelligente Dokumentenanalyse
Systeme zur Dokumentenanalyse erledigen eine Vielzahl von Aufgaben, die ebenfalls mit ML Modellen erlernt und automatisiert werden können. Auch hierbei erfordert die jeweilige Aufgabenstellung spezialisierte Werkzeuge für eine möglichst produktive Nutzung in der Praxis.
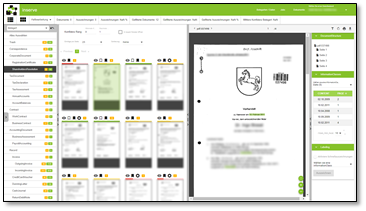
Zwei Beispiele hierfür sind die Klassifizierung von Belegarten und die Erkennung bestimmter Informationen innerhalb von Dokumenten:
Belegarten: Dokumente müssen gezielt selektiert und mit einem Mausklick der passenden Belegart zugewiesen werden können. – Durch Filter und visuelle Markierungen können wiederum schnell unsichere oder falsche Vorhersagen identifiziert werden.
Informationsklassen: Für eine bestimmte Klasse (z.B. Belegdatum) in Frage kommenden Informationen in Dokumenten (z.B. alle Datumsangaben) müssen gezielt erkannt und dann wiederum mit möglichst wenig Interaktionen ausgezeichnet werden können. Häufig ist die Vorhersage zu vieler Kandidaten („False Positives“) eine der größten Herausforderungen, so dass möglichst stark automatisiert geeignete Negativbeispiele ausgezeichnet werden müssen.
Auch hierbei ist die performante Interaktion zwischen Trainer und Modellen erfolgskritisch: Optimaler Weise zeichnet der Trainer ein Dokument aus und erhält mit minimaler Verzögerung neue Vorhersagen beziehungsweise Vorschläge vom System, welche Dokumente/Informationen als nächstes ausgezeichnet werden sollten, um Unsicherheiten zu beseitigen.
Haben Sie noch Fragen oder Anregungen zum Artikel? Dann kontaktieren Sie mich gerne direkt unter nfunke@agile-im.de
Diese Artikel könnten Sie auch interessieren:

Erfolgreicher Start für Prozessoptimierungen mit KI in der Logistik und in der Produktion: Der (Mehr)Wert eines Workshops

Die Grundsteine für erfolgreiche KI-Implementierung: Warum Machine Data Landscaping (MDL) und Data Quality Checks (DQC) unerlässlich sind

Fachkräftemangel in Unternehmen: Wie kann Industrielle KI hier unterstützen?

Lastspitzenmanagement mit AIM.predict: Wie Machine Learning Lastspitzen in der Energieversorgung reduziert

