Erfreulicherweise konnten wir in den letzten vier Jahren einen rapiden Anstieg des ernsthaften Interesses von Unternehmen am Innovationspotential von Industrieller KI und Machine Learning verzeichnen.
Seit Jahresbeginn haben mehrere hundert Teilnehmer unsere Webinare z.B. zu Predictive Supply Chain, Predictive Maintenance, Machine Vision, Intelligent DAM, Data Lakes und KI Plattformen besucht. Wir haben diese Gelegenheit genutzt, um die Sicht der Teilnehmer auf die Bedingungen für die Nutzung der Wettbewerbsvorteile durch KI zu erfragen. Interessanter Nebenaspekt: die meisten – ca. 80% der Teilnehmer stufen sich selbst als „KI Einsteiger“ ein. Zwar gehen viele bereits Anwendungsfälle an und sehen große Potentiale, aber viele nennen auch einige wesentliche Hürden, insbesondere folgende:
- „Wir wissen nicht wo wir anfangen sollen.“
- „Kein Budget vorhanden.“ / „Geschäftsführung ist nicht von KI überzeugt.“
- „Die Datenbasis fehlt.“
Aus der Erfahrung in erfolgreichen Kundenprojekten können wir einige Lösungsansätze vorschlagen:
Agilität und Streckenerfolge
Agiles Vorgehen z.B. nach Scrum oder Kanban ist in klassischen Software/IT Projekten fest etabliert und weitet sich zunehmend aus. Dieses Vorgehen ist besonders für komplexe Situationen geeignet, in denen sowohl bei Anforderungen, als auch Lösungen noch Neuland betreten wird. Dies ist bei KI Projekten für viele Unternehmen der Fall und zudem sind die Felder Data Science und Machine Learning ihrer Natur nach häufig sehr explorativ.
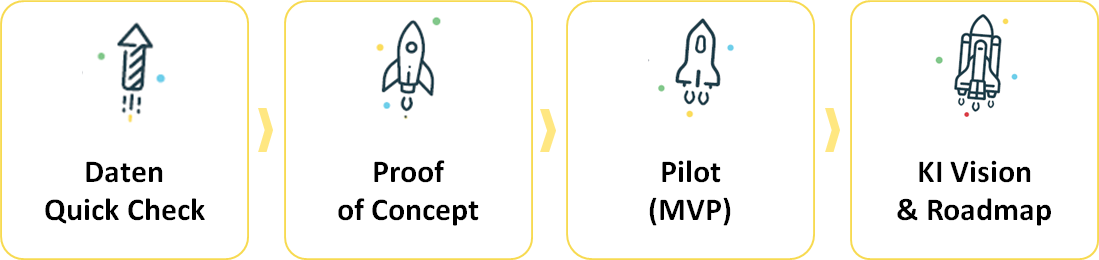
Durch ein iteratives Vorgehen mit definierten Zwischenschritten und zügigen, inkrementellen Ergebnissen können Sie mit geringem Aufwand schnelle Streckenerfolge erreichen. So schaffen Sie die Grundlage für Budgets und das weitere Vorgehen. Folgende Schritte haben sich bewährt:
(Data) Quick Check: Verwenden Sie die Daten, die vorhanden sind und lassen Sie in einer schnellen Exploration, Analyse und Visualisierung herausfinden, welche nutzbaren Muster sich in diesen verstecken und ob die gegebene Aufgabenstellung auf dieser Basis lösbar ist. Erfahrene Data Science/Engineering Teams können bereits mit 2-3 Tagen Arbeit wertvolle Ergebnisse hervorbringen und gleichzeitig helfen, Anforderungen und Erfolgsbedingungen zu schärfen. Unserer Erfahrung nach fallen dabei häufig schon interessante und neue Erkenntnisse über Prozesse, Kunden o.ä. als Nebenprodukt ab.
Proof of Concept: Wählen Sie ein bis zwei erste Anwendungsfälle aus und konkretisieren Sie Zielsetzungen und potentielle Mehrwerte. Wichtig ist dabei, von Beginn an eine Messlatte (z.B. Prognosequalität) als Erfolgskriterium zu vereinbaren. So können die fachlichen Anforderungen in formale Aufgaben für ein Machine Learning Modell übersetzt und die Machbarkeit zügig in einem Prototypen überprüft werden. In dieser Phase sollten Sie noch nicht eine bereits produktiv einsetzbare Lösung anstreben, aber mit den richtigen Werkzeugen und Methoden kann dies weitgehend vorbereitet werden.
Minimum Viable Product: Für die erste produktive Version sollte zunächst der kleinstmögliche Umfang (Minimum) realisiert werden, der aber bereits einen vollständigen Mehrwert (Viable) liefert. Auf dieser Basis können weitere Erkenntnisse gesammelt und die nächsten Schritte ökonomisch begründet werden. Auch dies ist keine neue Idee, aber in der Praxis ist häufig die Herausforderung, zunächst einmal Dinge wegzulassen, die noch nicht wirklich erforderlich sind.
Generell sollten bei diesem Vorgehen häufige Abstimmungen zwischen Anwendern, IT und dem Data Science/Engineering Team stattfinden, um gemeinsam den Fortschritt und die Ergebnisse im Blick zu behalten, fachliches Feedback einfließen zu lassen und das weitere Vorgehen zu justieren. Allerdings: ein Mindestmaß an Mut und Innovation gehört natürlich dazu, um ein zu frühes „kaputt rechnen“ zu vermeiden und den Prozess in Gang zu setzen.
Schulung + Potential Ermittlung
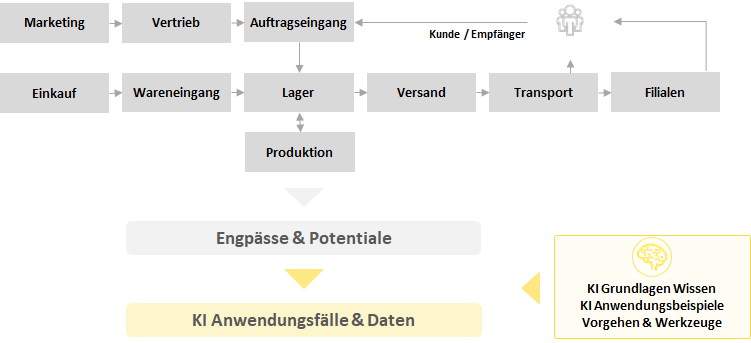
Künstliche Intelligenz ist einerseits durch Medien und Anbieter gehyped, aber andererseits fehlen häufig noch konkrete Vorstellungen über die echten Potentiale und Herausforderungen. Management und Fachspezialisten in Anwenderunternehmen müssen in die Lage versetzt werden, konkrete Ansatzpunkte für den Einsatz von KI für ihre operativen und strategischen Ziele zu finden.
In unserer Praxis hat sich hierfür ein Workshop Format bewährt, in dem in 1-2 Tagen eine Schulung zu KI Grundlagen mit der Ableitung konkreter Potentiale aus den Prozessen und wesentlichen Engpässen des Unternehmens kombiniert wird. So kann Ihr Team besser informierte Entscheidungen treffen und erstellt dabei gleich eine konkrete Roadmap für die Umsetzung oder kommt zu der begründeten Schlussfolgerung, dass KI (noch) keinen Mehrwert für Ihr Unternehmen hat.
Daten sammeln & erproben + Data Engineering
Aktuell stellen Unternehmen, die bereits mit der Realisierung von KI Anwendungen begonnen haben, häufig fest, dass die Datengrundlagen nicht oder nur eingeschränkt vorhanden sind. Dies hat vielfältige Gründe, zum Beispiel:
- Schnittstellen zu den entsprechenden Quellsystemen fehlen
- Für KI Aufgaben relevante operative Daten werden nicht historisiert
- Insbesondere unstrukturierte Daten (Bilder, Videos, Dokumente) liegen in Silos
- Zusätzliche externe Informationen werden benötigt
- Die eigentlichen Trainingsdaten („Ground Truth“) sind bisher nicht vorhanden
Über geeignete Werkzeuge, die Feedback Schleifen mit den operativen Anwendern („Human in the Loop“) oder spezialisierte Dienstleister wie AIM oder unsere Kooperationspartnerin inserve GmbH (Intelligent Document Management) können zügig und effizient Trainingsdaten ausgezeichnet werden. Insbesondere für Predictive und Prescriptive Analytics Anwendungen stehen zunehmend standardisierte externe Datenquellen zur Verfügung – z.B. für Wetter-, Verkehrs- und Wirtschaftsdaten.
Lösungsansätze im Predictive Maintenance Bereich sind herausfordernder: durch die Zusammenarbeit mit Komponenten, Sensorik und IoT Herstellern realisieren wir spezifische Lösungen, die bestehende Produkte ergänzen. Für Betreiber von Maschinen/Anlagen, aber auch generell gilt: analog zu dem vorher beschriebenen Vorgehen, sollte zunächst einmal verprobt werden, was mit den vorhandenen Daten bereits erreicht werden kann! Erfahrene Data Scientists können tatsächlich häufig versteckte Informationsschätze heben, die vorher nicht sichtbar waren.
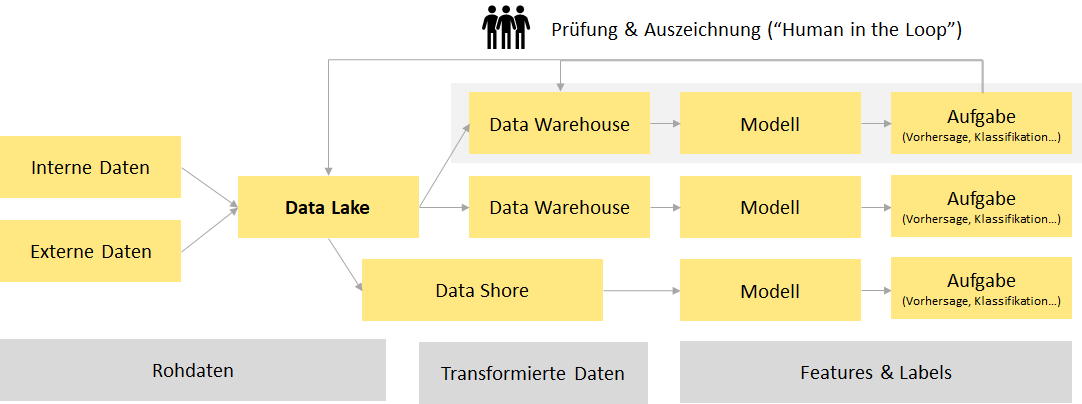
Parallel kann ebenfalls in kleinen Schritten schon damit begonnen werden, die verfügbaren Daten, die bisher nicht in einem Data Warehouse oder den operativen Systemen erfassten worden sind, in einem Data Lake zu sammeln. Dieser Ansatz kann mit den erreichten Streckenerfolgen sukzessiv zu einem vollwertigen Data Engineering ausgebaut werden.
Nächster Schritt: Plattform für Produktivitätssteigerung aufbauen
Die ersten Prototypen und MVPs (Minimum Viable Products) können zügig, pragmatisch und direkt als eigenständige KI Services realisiert werden, die Sie in ihre bestehenden Anwendungen einbinden. Je nach Aufstellung Ihrer IT können Sie diese On Premise betreiben oder als Managed Service bzw. aus der Cloud beziehen.
Nimmt Ihre KI Roadmap Fahrt auf und/oder wollen Sie ein eigenes Team aufbauen, ist es empfehlenswert, schrittweise eine KI Plattform aufzubauen, um die Produktivität der Umsetzung sowie Qualität, Skalierbarkeit und Robustheit zu steigern.
Dies bedeutet aber wiederum nicht, dass Sie erst einmal ein komplexes und großes Technologie Projekt starten müssen. Vielmehr ist es sinnvoll, Ihre Vorgehensweisen, Methoden und Werkzeuge kontinuierlich zu verbessern und in Ihren Teams zu verankern. Hierfür können Sie z.B. unsere Erfahrungswerte sowie existierende Blaupausen und Komponenten nutzen.
Hat Ihnen dieser Artikel weiter geholfen und Ideen gegeben? Möchten Sie die genannten Hürden aus dem Weg schaffen? Über Ihr Feedback und Anregungen freue ich mich.
Haben Sie Fragen oder brauchen Hilfe bei der Beseitigung von Hürden für die Nutzung von KI in Ihrem Unternehmen? Dann nehmen Sie jetzt Kontakt auf:
E-Mail: aarora@agile-im.de
Diese Artikel könnten Sie auch interessieren:

Die Sicherheit von Kundendaten: Atlassian Cloud vs. Eigene Server
In der heutigen digitalen Welt ist die Sicherheit von Daten ein zentrales Anliegen für Unternehmen und Kund:innen. Insbesondere wenn es um die Speicherung sensibler Informationen geht, stehen Firmen vor der Herausforderung, die richtige Balance zwischen Komfort und Sicherheit zu finden. Doch welche Option bietet letztendlich die beste Sicherheitslösung: die Cloud oder der eigene Server im Keller?

Erfolgreicher Start für Prozessoptimierungen mit KI in der Logistik und in der Produktion: Der (Mehr)Wert eines Workshops
In diesem Artikel beleuchten wir die Relevanz der Startphase von KI-Projekten im logistischen und industriellen Umfeld und erklären, warum ein Workshop der Schlüssel zur erfolgreichen Prozessoptimierung ist.

Gemeinsam lernen: Die Ausbildung zum Fachinformatiker bei AIM
Was macht ein Fachinformatiker für Anwendungsentwicklung? Das haben wir unseren Azubi Louis gefragt: Erfahre jetzt mehr aus seinem Alltag und was er an AIM besonders schätzt.
