
Bei der Planung von Machine Learning Projekten gelangen wir regelmäßig zu der Frage, ob denn genügend Daten zur Verfügung stehen, um eine relevante Vorhersage oder eine Optimierung durch eine Machine Learning-Anwendung zu erreichen. Dabei spielt nicht nur die rohe Menge der Daten eine Rolle, häufig ist die Historisierung dieser Daten wichtiger. Als Teil dieser Diskussion kommt nicht selten ein vorhandenes Data Warehouse (DWH) ins Spiel. Darum muss in der Regel erst einmal betrachtet werden, was der Unterschied zwischen einem DWH und einem Data Lake ist.
Warum ein Data Lake und kein Data Warehouse
Ein DWH strukturiert Daten aus verschiedenen Quellen und stellt sie für Prozesse, Anwendungen oder Schnittstellen zur Verfügung. Ein Data Scientist würde an dieser Stelle schon entmutigt auf den Datenverlust hinweisen, den allein die Konvertierung in ein zentrales Schema verursacht. Ein Data Lake ersetzt kein DWH, es bietet einen Speicherort für rohe Quelldaten. Diese Daten werden weder vereinheitlicht noch angereichert, denn das würde mit einem Datenverlust einhergehen. Dem Data Scientist bleiben damit alle Möglichkeiten der Analyse.
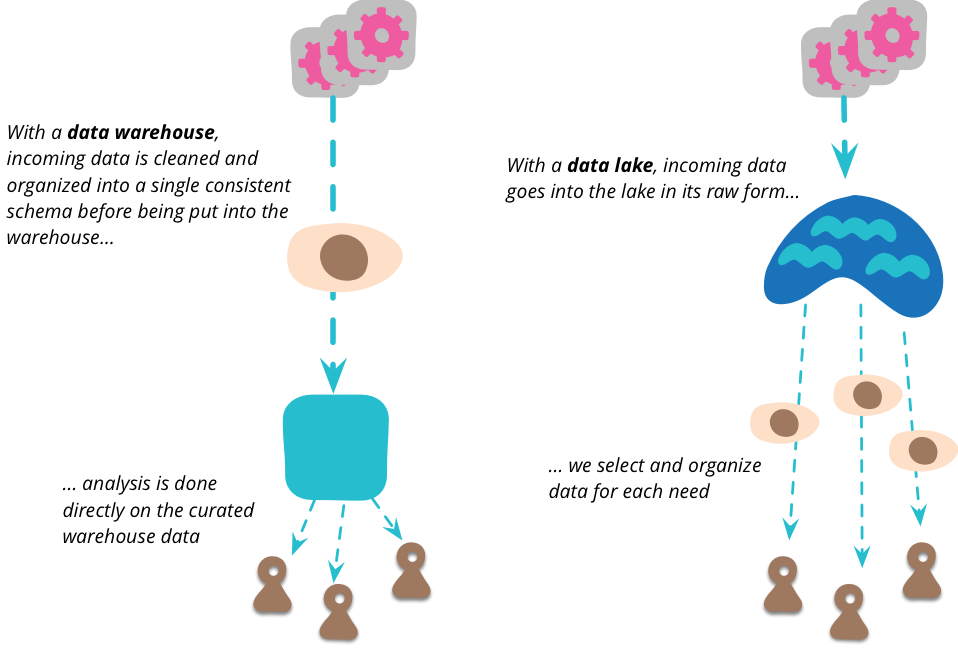
[Bildquelle: Martin Fowler| martinfowler.com]
Extraktion – Flaschenhälse vermeiden
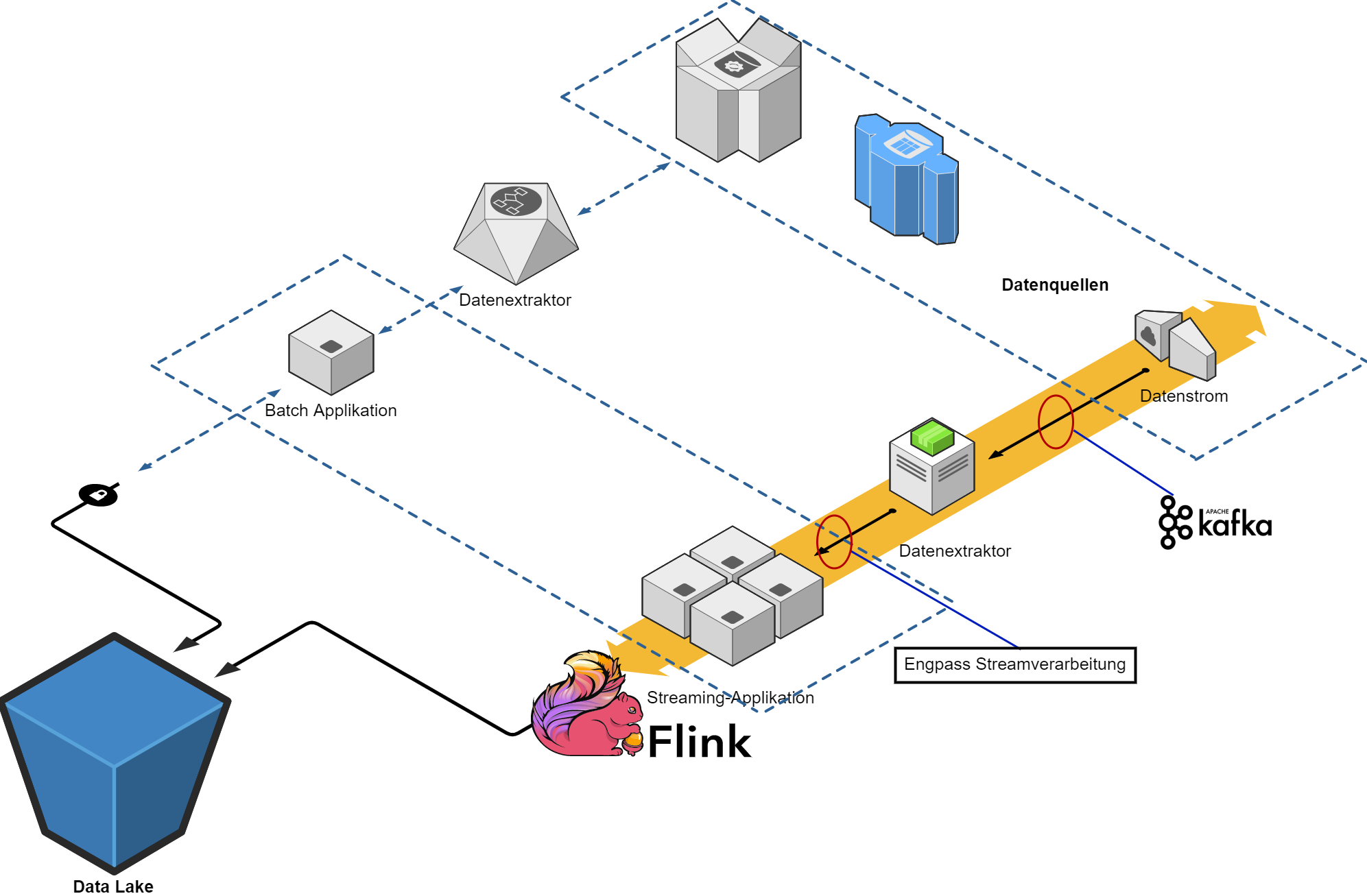
Auch wenn ein Data Lake „nur“ ein großer Datenspeicher für alle möglichen Datenformate ist, darf hier die Konsistenz der Daten nicht vergessen werden. Wenn Teile der abgelegten Daten abhandenkommen, kann das einen großen Effekt auf die Datenqualität und somit auf die Genauigkeit späterer Lösungen haben. Deshalb sollte auch beim Planen eines Data Lake die transaktionssichere Ablage berücksichtigt werden. In unseren Projekten haben wir die Erfahrung gemacht, dass Kafka hier seine Stärken hat. Kafka bietet eine transaktionale, nachvollziehbare und persistente Kommunikationsplattform für die meisten Datenquellen. Kafka lässt sich zudem auch direkt an ein Prometheus/Graphana basiertes Monitoring anbinden. Durch den Einsatz von Kafka kann man zu befürchtenden „Backpressure“ vermeiden und hat gleichzeitig eine ausfallsichere Umgebung für alle eingehenden Quellen eines Data Lake.
Tipps vom Profi im Data Lake Web-Seminar

Unser Experte Carsten Hilber zeigt Ihnen im Data Lake Web-Seminar: wie Sie mit einem Data Lake eine zentrale Datenablage anlegen können, um jeder zukünftigen, innovativen Anforderung gerecht zu werden.
Datenspeicherung – Plattformunabhängigkeit und Kostenbetrachtung
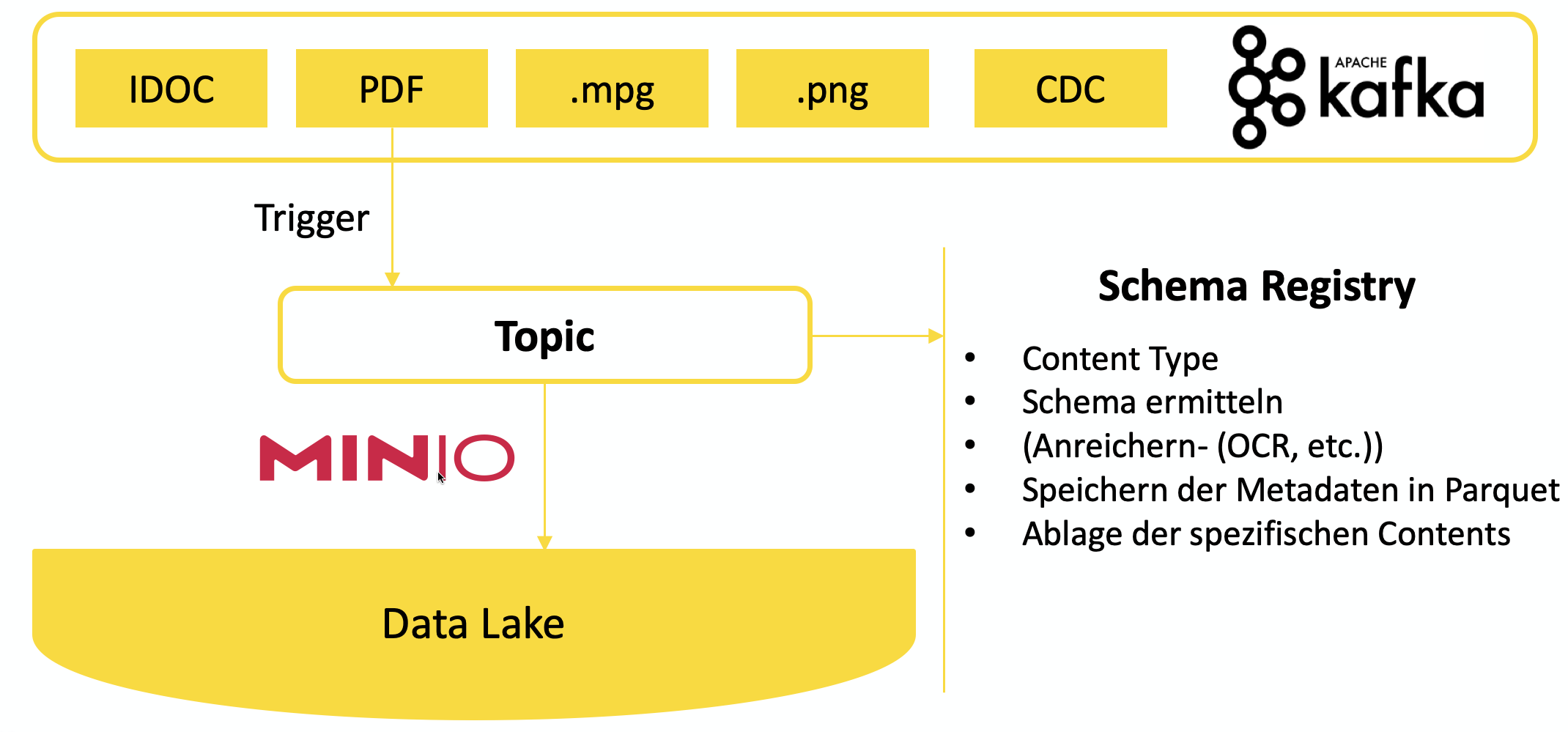
Man könnte denken, dass das Speichern der Daten keine so schwierige Aufgabe sein sollte, doch vergisst man schnell ein paar limitierende Faktoren. Mit einem wachsendem Volumen der Ablage kommt man schnell an Grenzen, sodass man sich nach Alternativen umschaut. Die schieren Kosten der Datenablage, aber auch Regulierungen des Gesetzgebers, wie zuletzt die DSGVO, können schnell dazu führen, dass man den Ort der Ablage ändern muss. Da unsere Projektsituationen ohnehin eine gewisse Unabhängigkeit von Cloud Plattformen Anbietern wie Azure, AWS oder Google bieten muss, verwenden wir eine einheitliche Anbindung an unabhängige Speicherorte durch MinIO. Dadurch können wir den Zugriff auf den Data Lake ebenfalls vereinheitlichen, sodass der Data Scientist seine Analyse völlig unabhängig von dem genutzten Medium durchführen kann.
Jedem sein Model
Ein Data Lake wird von wenigen Personen, meist von Data Scientists verwendet. Ein Data Lake ist normalerweise nicht dazu geeignet, direkt an APIs angebunden zu werden. Viel mehr dient er zur Analyse und als Grundlage für spezifische Lakeshores, also Ufer an denen sich Applikationen mit einem spezifischen, gebundenem Kontext und auch eigenem Modell. Damit wird die direkte Lösungsarchitektur für eine einzelne Lösung klarer und auch einfacher abzubilden.
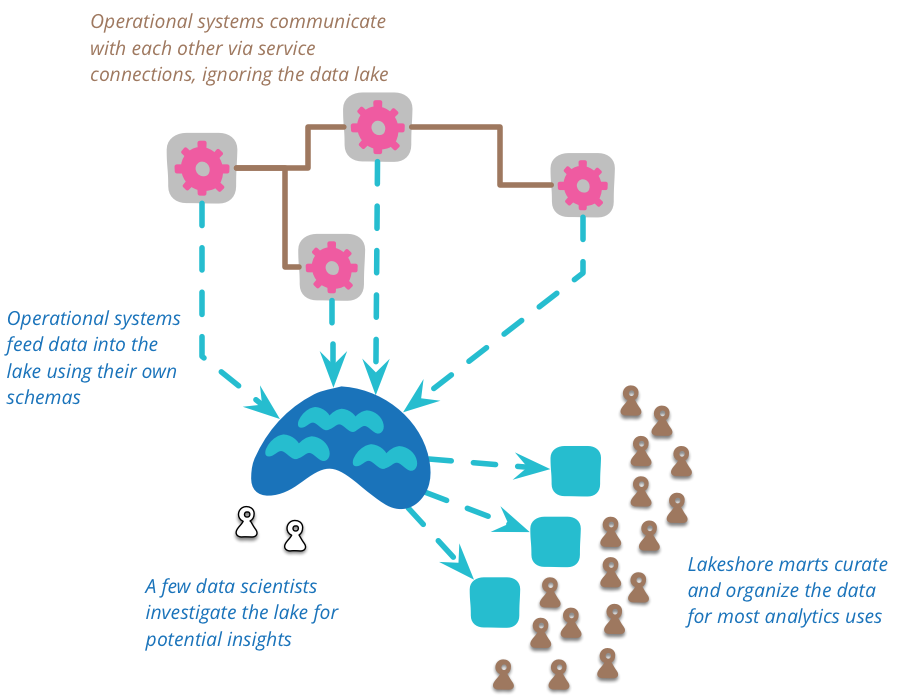
[Bildquelle: Martin Fowler| martinfowler.com]
Suchen in einem Data Lake
Martin Fowler sagte in seinem Artikel über Data Lakes, dass anders als bei einem DWH das Problem der Nutzung der Daten beim Konsumenten liegt. Man solle also beim Einführen eines Data Lake nicht zwangsläufig die zu verwendeten Suchmethoden in den Vordergrund stellen. Was einem später die Suche erleichtern kann, ist aber die Ablage im Parquet Format. Dadurch können Metadaten der eigentlich abgelegten Daten hinzugefügt werden. Spätere Suchen im Data Lake werden somit vereinfacht, auch das Anreichern von Daten im PDF oder in den gängigen Bild-Formaten wird anhand der Metadaten ermöglicht.
Fazit
Data Lakes stehen also für eine erweiterte Analysemöglichkeit aller Unternehmensdaten und nicht in Konkurrenz zum DWH. Da ein Data Lake eher von wenigen Personen und nur zur Analyse nutzbarer Unternehmensdaten herangezogen wird, steht hier die Extraktion und Speicherung der Daten im Vordergrund. Viele Projektsituationen haben gezeigt, dass die strukturiert zugänglichen Daten oft nicht die Informationen enthalten, die man für Prognosen in Machine Learning-Anwendungen benötigt. In vielen Fällen führte dies dazu, dass diese Unternehmen einen Data Lake eingeführt haben, um in Zukunft alle Daten heranziehen zu können.
Sie möchten noch mehr zum Thema Data Lake von unserem Experten Carsten Hilber lesen? Dann sollten Sie auf keinen Fall den neuen Artikel: „Wie sammelt man Rohdaten im Data Lake?“ im IT & Produktion Online Magazin verpassen.
Haben Sie noch Fragen oder Anregungen zum Artikel? Dann kontaktieren Sie mich gerne direkt unter chilber@agile-im.de
Diese Artikel könnten Sie auch interessieren:

Die Sicherheit von Kundendaten: Atlassian Cloud vs. Eigene Server
In der heutigen digitalen Welt ist die Sicherheit von Daten ein zentrales Anliegen für Unternehmen und Kund:innen. Insbesondere wenn es um die Speicherung sensibler Informationen geht, stehen Firmen vor der Herausforderung, die richtige Balance zwischen Komfort und Sicherheit zu finden. Doch welche Option bietet letztendlich die beste Sicherheitslösung: die Cloud oder der eigene Server im Keller?

Erfolgreicher Start für Prozessoptimierungen mit KI in der Logistik und in der Produktion: Der (Mehr)Wert eines Workshops
In diesem Artikel beleuchten wir die Relevanz der Startphase von KI-Projekten im logistischen und industriellen Umfeld und erklären, warum ein Workshop der Schlüssel zur erfolgreichen Prozessoptimierung ist.

Gemeinsam lernen: Die Ausbildung zum Fachinformatiker bei AIM
Was macht ein Fachinformatiker für Anwendungsentwicklung? Das haben wir unseren Azubi Louis gefragt: Erfahre jetzt mehr aus seinem Alltag und was er an AIM besonders schätzt.
