
Herausforderung: Zielgerichtetes Design Neuronaler Netze
Die Eigenschaften von neuronalen Netzen sind maßgeblich durch ihre Neuroarchitektur bestimmt. Leider ist es bisher sehr schwer, diese Architekturen zielgerichtet zu designen und erfordert viele explorative Experimente. Der Grund hierfür ist mangelnde Einsicht in die Informationsverarbeitung eines Netzes.
Durch einfache Vergleiche der Metriken kann zwar gesagt werden, ob Netz X bessere Vorhersagen macht oder schneller rechnet als Netz Y – nicht jedoch, warum es dies tut. Um den Entwicklungsprozesse schneller und deterministischer zu gestalten, haben wir in den letzten Monaten Analyseverfahren entwickelt, welche dem Entwickler bessere Einsicht in das trainierte Netzwerk gewähren. Dadurch ist es dem Entwickler möglich, gezieltere Entscheidungen zu treffen und somit den Designprozess weniger erratisch zu durchlaufen. Bei Trainingslaufzeiten von mehreren Stunden bis Tagen auf moderner Hardware und dutzenden Grafikkarten bedeutet dies einen signifikanten Gewinn an Produktivität.
Ein Flussbett aus Neuronen
Ein gutes neuronales Netz für ein bestimmtes Problem ist gerade komplex genug, um die Aufgabenstellung gezielt zu lösen, ohne dabei mehr Rechenleistung als nötig zu verbrauchen. Beim Design von Netzen geht es also darum, die Auslastung ihrer Architektur zu optimieren. Betrachten wir hierfür das Netzwerk als eine Art Flussbett und die Informationen, die durch das Netzwerk propagiert werden, als Wasser. Idealerweise wollen wir nicht die Ressourcen aufwenden, um einen Panamakanal ausbuddeln, wenn nicht unbedingt nötig. Auf der anderen Seite wird ein zu kleines Flussbett überlaufen, es gehen also Informationen verloren, was sich negativ auf die Vorhersageleistung auswirkt.
Das Netzwerk spannt einen Raum auf und muss auf die durchfließenden Informationen abgestimmt werden. Wie groß das Flussbett in unserer Metapher ist, lässt sich leicht ermitteln. In jeder Neuronenschicht (Layer) befindet sich ein sogenannter “Feature Space”, der durch die Parameter aller Neuronen im jeweiligen Layer aufgespannt wird. Der jeweilige Layer stellt die Breite des Flussbetts dar. Da wir Wissen wie viele Inputs und Outputs ein Layer hat, ist die Dimensionalität des Feature Space bekannt. Mit anderen Worten, wenn wir ein Flussbett selbst ausbuddeln, wissen wir auch wie breit es ist. Der Raum, den die Informationen in einer beliebigen Neuronenschicht einnehmen, ist dagegen schwieriger zu ermitteln.
Vorsicht vor Datenüberschwemmung – Informationsverlust droht
Hierfür betrachten wir die latenten Repräsentationen der Trainingsdaten. Latente Repräsentationen sind Zwischenzustände, welche die Daten durchlaufen, während sie durch das Netzwerk fließen. Durch statistische PCA (Principal Component Analysis) Verfahren lässt sich ermitteln, wie viele räumliche Dimensionen des Feature Space die latenten Repräsentationen in einer Schicht oder im ganzen Netzwerk einnehmen.
Da die latenten Repräsentationen innerhalb des Feature Space existieren, wird die Anzahl ihrer Dimensionen immer gleich oder geringer sein als die des Feature Space. Teilen wir die Dimension der latenten Repräsentation durch die des Feature Space erhalten wir einen Prozentwert, der effektiv aussagt wie viel “Raum” die latenten Repräsentationen einnehmen. Diesen Wert nennen wir “Sättigung”. In der Fluss-Metapher stellt der Sättigungswert in gewisser Weise den prozentualen Füllstand des Flussbettes dar.
Haben wir eine Sättigung näher oder sogar gleich 1.0 ist das Netzwerk stark ausgelastet – Informationen gehen verloren und die Vorhersageleistung leidet. Ist dieser Sättigungswert hingegen nahe bei 0, benötigen die latenten Repräsentationen nur einen Bruchteil des verfügbaren Raumes. Das Flussbett ist also zu groß. Wir können vermutlich gleiche oder leicht bessere Vorhersageleistung erreichen, indem wir weniger komplexe Netze trainieren.
Sättigung als Werkzeug im Design-Prozess Neuronaler Netze
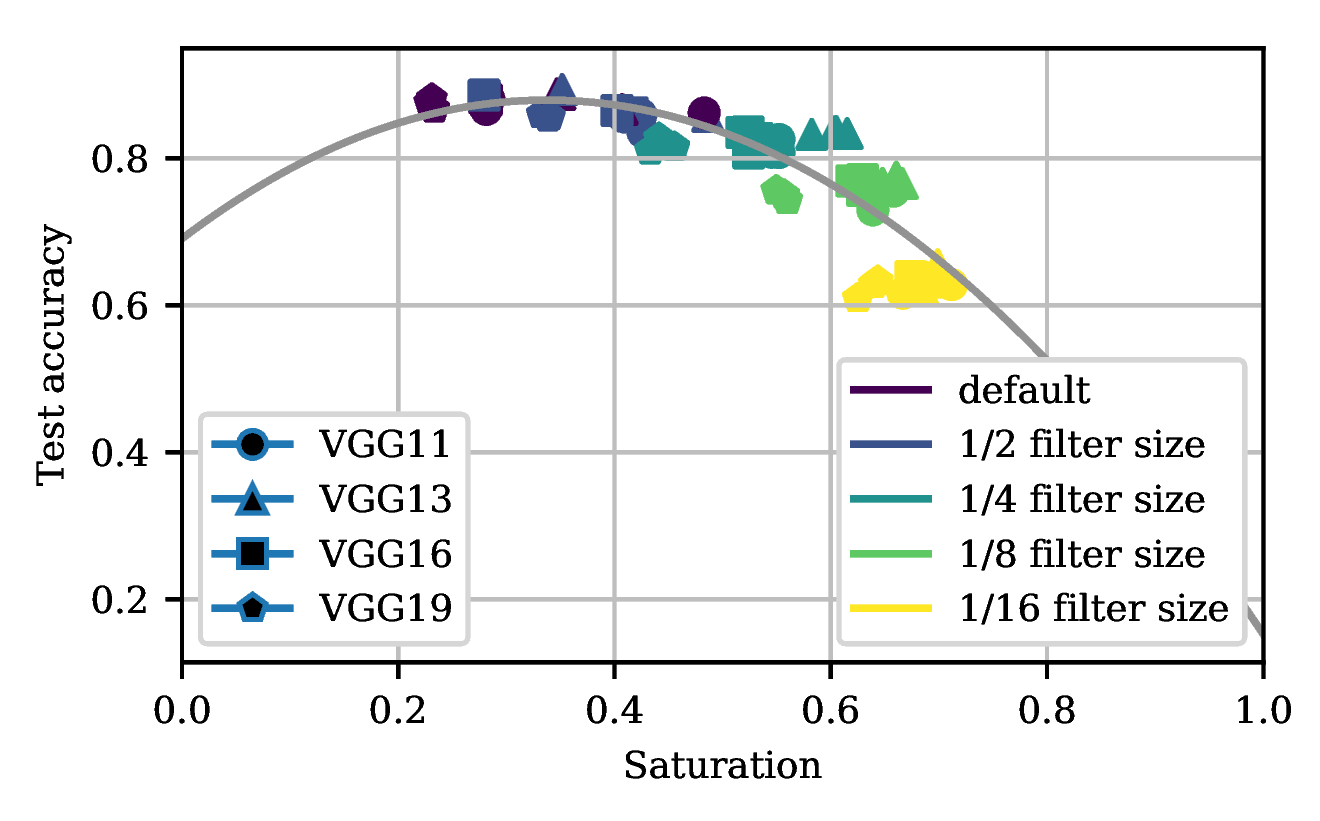
In der oben gezeigten Abbildung sehen wir diverse Netzwerke, die auf dem selben Problem trainiert wurden. Je heller dabei die Farbe eines Punktes, desto einfacher und kleiner ist die Architektur. Wie wir sehen, nimmt die Vorhersageleistung (y-Achse, gemessen in Accuracy) zu, wenn die Architektur komplexer wird. Wie an dem Beispiel mit Flussbett erläutert, lässt sich auch erkennen, dass die Sättigung mit steigender Komplexität abnimmt. Dieses Verhältnis von Komplexität und Vorhersageleistung ist jedoch nicht linear. Ist der Leistungsgewinn bei spätestens 20-30% durchschnittlicher Sättigung ausgereizt, profitieren wir nicht mehr wesentlich von zusätzlicher Komplexität. Für den Entwickler bedeutet dies, dass leicht Identifiziert werden kann, wie komplex ein Netzwerk für ein vorhandenes Problem sein muss. 20-30% bieten i.d.R. das beste Verhältnis von Rechenleistung / Vorhersageleistung, während alles über 40-50% Sättigung deutlich zu simpel gestrickt ist.
Genug Schichten
Zu wenige Neuronen
Zu viele Schichten
Genug Neuronen
Genau Richtig
Design in Balance
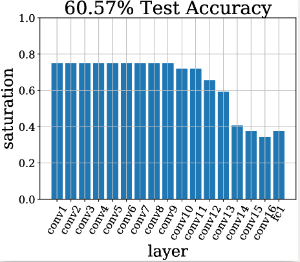
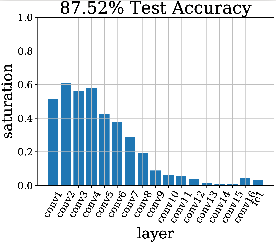
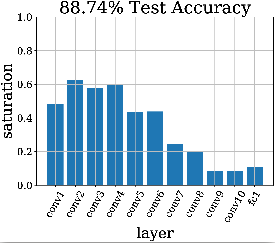
Die Sättigung lässt sich auch für das Design einer einzelnen Architektur nutzen, ohne dutzende Modelle auf ein Problem los zu lassen. Die Balkendiagramme stellen jeweils ein trainiertes Modell dar, wobei jeder Balken die Sättigung einer Neuronenschicht darstellt.
Wie zu sehen ist, hat Netzwerk (a) zwar viele Schichten, aber zu wenige Neuronen. Dies schlägt sich in hoher Sättigung und schlechter Leistung nieder. Hier müsste also die Anzahl der Neuronen pro Schicht erhöht werden. In Abbildung (b) sehen wir den Effekt dieser Änderung. Nun ist die Sättigung gegen Ende niedrig („Longtail“). Die Vorhersageleistung ist zwar deutlich verbessert worden, aber die Architektur ist nun sehr groß und unhandlich. Da die letzten Schichten kaum genutzt werden, wie wir anhand der geringen Sättigung sehen, kürzen wir das Netzwerk. Das resultierende Netzwerk ist in Abbildung (c) zu sehen. Hier sehen wir eine ideale Verteilung der Sättigung in einer Neuroarchitektur. Die Leistung hat sich nur noch leicht verbessert, aber die benötigte Rechenleistung konnte aber von (b) zu (c) halbiert werden.
Unser Forschungspapier zu diesem Thema ist derzeit im Vordruck für das Journal „IEEE – Transaction in Pattern Analysis and Machine Intelligence“. Erhalten Sie hier eine öffentlich zugängliche Variante: https://arxiv.org/abs/1907.08589
Haben Sie noch Fragen zum Artikel „Ein Werkzeug für effizientes Design Neuronaler Netze“? Dann kontaktieren Sie mich gerne direkt unter nfunke@agile-im.de
Diese Artikel könnten Sie auch interessieren:

Erfolgreicher Start für Prozessoptimierungen mit KI in der Logistik und in der Produktion: Der (Mehr)Wert eines Workshops

Die Grundsteine für erfolgreiche KI-Implementierung: Warum Machine Data Landscaping (MDL) und Data Quality Checks (DQC) unerlässlich sind

Fachkräftemangel in Unternehmen: Wie kann Industrielle KI hier unterstützen?

Lastspitzenmanagement mit AIM.predict: Wie Machine Learning Lastspitzen in der Energieversorgung reduziert

