Megatrend Machine Learning
Machine Learning (ML) und künstliche Intelligenz (AI) gehören zu den heißesten aktuellen Trends in IT, Wirtschaft, Medien und sogar der Filmbranche.
Getrieben wird dies durch Faktoren wie z.B. eine Intensivierung der neurowissenschaftlichen Forschung (Human Brain Project, Blue Brain Project), massiv wachsenden Daten = Big Data, zunehmender Virtualisierung und Verbilligung von Rechnerkapazitäten sowie Entwicklung spezieller Hardware z.B. für Deep Neuronal Networks (Nervana).
Zwischen teilweise abenteuerlich-romantischen Vorstellungen, die auch in Kino Filmen wie „I, Robot“, „She“ oder „Ex Machina“ Einzug gefunden haben, und echten Anwendungen für praktische Probleme liegen aber (noch) Welten.
Was ML Lösungen aber derzeit bereits leisten können, ist die Erkennung von Mustern in großen, dynamischen, heterogenen – sprich komplexen – Daten. Wesentliche Aufgabenbereiche sind Klassifizierung, Vorhersage, Verarbeitung und Erzeugung natürlicher Sprache sowie von Bildern und Videos.
Hierzu kommen tatsächlich ein riesiger Blumenstrauß von Verfahren zum Einsatz – z.B. klassisch-statistische, probabilistische, linguistische und – derzeit sehr im Fokus der Aufmerksamkeit – neuronale Netze mit zunehmend ausgefeilteren Architekturen (z.B. Convolutional Nets orientiert am menschlichen visuellen System).
Erfolgsfaktoren echter Anwendungen
In der Praxis benötigt man vor allem folgende Zutaten für erfolgreiche Machine Learning Lösungen:
- Eine Problemstellung, die das Erkennen von Mustern in komplexen Daten erfordert.
- Fundierte Kenntnisse in Algorithmen für Feature Extraktion, Sprachverarbeitung, Klassifizierung und Regression.
- Flexible Kombination der Algorithmen in sogenannten ML Pipelines und Evaluierung durch Experimente.
- Ergonomische Werkzeuge für Training des Systems und Visualisierung erkannter Muster.
- Ein agiler DevOps Prozess, der die hoch iterative Erprobung von Algorithmen ermöglicht.
- Verfügbarkeit nach Bedarf hoch skalierbarer Rechner Ressourcen.
Legaltech Startup mit hohem Mehrwert
Genau diese Erfolgsvoraussetzungen hat AIM seit Anfang des Jahres für ein vielversprechendes Legaltech Startup geschaffen. Dessen Geschäftsmodell basiert im Kern auf der intelligenten, automatisierten Analyse großer, heterogener Mengen kaufmännischer Dokumente.
Die bisherige aufwändige, fehlerträchtige und unvollständige Suche in Aktenordnern und analogen Dokumenten entfällt hierdurch. Wesentlicher ist aber, dass kritische kaufmännische und rechtliche Informationen extrahiert werden, die manuell in dieser Breite und Tiefe bisher gar nicht mit angemessenem Aufwand zugänglich waren.
Lösungskonzept
Die analog vorliegenden Dokumente werden über Hochleistungsscanner digitalisiert. Eine Texterkennung (OCR) liefert strukturierte Texte, die mit den eingescannten Bildinformationen in PDF Dokumenten kombiniert werden:
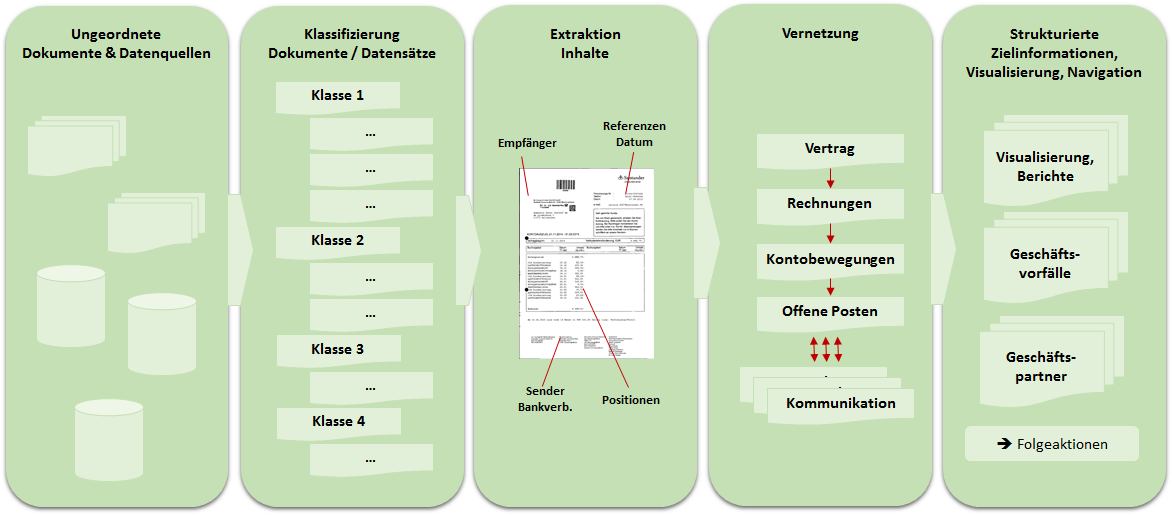
Die Lösung wird im Vollausbau dann durch Heuristiken und Machine Learning Algorithmen schrittweise die für den Endanwender relevanten Informationen durch folgende vernetzte Funktionen ermitteln und integrieren:
- Potentiell relevante Features werden aus den Rohdaten extrahiert.
- Die riesigen, sehr „verunreinigten“ und verrauschten Mengen an Features werden bereinigt.
- Die Rohdokumente werden nach kaufmännischen Belegarten klassifiziert.
- Spezielle Inhalte werden extrahiert und die Informationen durch zusätzliche Datenquellen angereichert.
- Die unstrukturierten Dokumente werden in strukturierte und verknüpfte Informationen transformiert.
- Der eigentliche Endanwender kann dabei einfach und gezielt spezielle Informationen und Geschäftsvorfälle finden.
Das System musst dabei zunächst mit Beispielen trainiert werden – dies wird aber mit jedem bearbeiteten Fall weniger notwendig, da das System zunehmend lernt.
Technologie
Die grundlegende Architektur basiert auf den als Open Source (Apache Lizenz 2.0) verfügbaren Machine Learning Frameworks Apache Spark / Mlib sowie deeplearning4j.
Dadurch stehen zum einen grundsätzliche Mechanismen z.B. für die verteilte Verarbeitung variabler Feature Vektoren und die Kombination parallel und sequentiell arbeitender Algorithmen in Pipelines zur Verfügung. Zum anderen werden viele sogenannte Transformers und Estimators (z.B. Decision Trees, Neuronale Netze, Clustering, Word2Vec) zur Verfügung gestellt.
Apache Spark erlaubt außerdem, bei hohen Anforderungen an Rechenleistung und Speicher die realisierten Anwendungen nach aktuellem Bedarf auf Rechner Cluster in der Private oder Public Cloud wie zum Beispiel Amazon Web Services zu verteilen.
Beitrag von AIM
Anfang des Jahres wurde AIM mit der Aufgabenstellung betraut, möglichst schnell die Problemstellung zu analysieren, die technologische Machbarkeit zu validieren und die notwendigen Voraussetzungen zu schaffen. Machine Learning ist – neben Agilität und DevOps – einer der wichtigsten fachlichen Schwerpunkte von AIM.
In dieser Zeit sind eine klare Strategie, ein leistungsfähiges Team, die benötigte DevOps Infrastruktur auf Atlassian Basis und ein erste Version der Lösung (Minimum Viable Product) als Grundlage für die nächste Phase aufgebaut worden.
Sind Sie ebenfalls interessiert an den Möglichkeiten von Machine Learning? Dann nehmen Sie Kontakt mit uns auf! Wir freuen uns auf einen Austausch zu Machine Learning und Apache Spark.
Apache Spark, Spark, Apache, und das Spark Logo sind trademarks von The Apache Software Foundation.
